

Navigating the Depths of Data Lakes
August 28, 2023In the era of big data, organizations are generating and collecting vast amounts of information from various sources such as IoT devices, social media platforms, customer interactions, and more. This deluge of data presents both an opportunity and a challenge for businesses looking to extract meaningful insights to drive decision-making. Enter the concept of a “Data Lake” – a centralized repository that allows organizations to store, manage, and analyze diverse data types at scale. This article explores the intricacies of data lakes, their benefits, and their role in modern data-driven enterprises.
A Data Lake is a storage repository that can centralize and store vast amounts of raw data in its native format. The data can be structured, semi-structured, or unstructured. The data structure and requirements are not defined until the data is needed, at read-time. This essentially means that Data Lakes create a future-proof environment for raw data, unconstrained and unfiltered by traditional, strict database rules and relations at write-time. The ingested raw data is always there, and can be re-interpreted and analyzed as needed.
Understanding Data Lakes
A data lake is a flexible and scalable storage solution that enables organizations to store vast volumes of raw and processed data in its native format. Unlike traditional relational databases, data lakes are not confined by a predefined schema. Instead, they accommodate structured, semi-structured, and unstructured data, providing a holistic view of an organization’s data landscape.
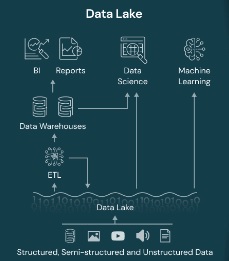
Key Components and Process Flow
- Data Ingestion and Collection: Raw data from various sources, such as databases, applications, external APIs, and streaming platforms, are ingested into the data lake. This initial step ensures that all relevant data is available for analysis.
- Data Storage (Data Lake): The data lake serves as the central repository, housing data in its original form. Data lakes can be built on distributed file systems, cloud-based storage, or hybrid solutions.
- Data Processing and Transformation: In this phase, data undergoes processing and transformation to enhance its quality and usability. This can include tasks like data cleaning, enrichment, normalization, and integration. Tools like Apache Spark, Apache Hadoop, and Apache Flink are commonly used for data processing in data lakes.
- Data Analysis and Visualization: Once the data is refined, it becomes accessible for analysis. Data scientists, analysts, and other stakeholders can leverage various analytics tools and platforms to extract insights, perform machine learning, and create visualizations that aid in decision-making.
Benefits of Data Lakes
- Scalability: Data lakes can handle massive volumes of data, making them suitable for businesses experiencing rapid data growth.
- Flexibility: Data lakes accommodate diverse data types without requiring upfront schema design, offering agility in data management.
- Cost-Effectiveness: Cloud-based data lakes allow organizations to pay for the storage they use, reducing the need for upfront infrastructure investments.
- Data Democratization: Data lakes empower a broader range of users to access and analyze data, fostering a culture of data-driven decision-making.
- Advanced Analytics: By centralizing data, data lakes facilitate advanced analytics, including machine learning, predictive modeling, and real-time analytics.
Challenges and Considerations
While data lakes offer numerous benefits, they also present challenges:
- Data Governance: Without proper governance, data lakes can become data swamps, leading to data quality and security issues.
- Data Security: As data lakes accumulate sensitive information, robust security measures are essential to prevent unauthorized access and breaches.
- Data Cataloging: To ensure data discoverability and usability, a comprehensive data cataloging strategy is crucial.
- Complexity: Data lakes involve complex architecture and require specialized skills for implementation and management.
Conclusion In the age of information, harnessing the power of data is a competitive imperative. Data lakes emerge as a strategic asset, offering organizations the ability to store, manage, and analyze data at an unprecedented scale and flexibility. While challenges exist, careful planning and implementation can transform data lakes into invaluable resources that drive innovation and enable data-driven decision-making. By embracing data lakes, businesses can navigate the depths of their data to uncover insights that fuel growth and success.
