An Introduction to Convolution Neural Network
August 29, 2023Convolutional Neural Networks (CNNs) are a specialized class of artificial neural networks designed primarily for processing and analyzing visual data, such as images and videos. They are highly effective in tasks like image classification, object detection, facial recognition, and more. CNNs have revolutionized the field of computer vision by enabling machines to learn and extract meaningful features directly from raw pixel data.
Key Concepts:
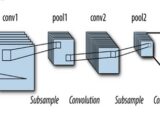
1)Convolutional Layers: The core idea behind CNNs is the use of convolutional layers. A convolution involves sliding a small filter (also known as a kernel) over the input image.
2) Pooling Layers: Pooling layers, often referred to as subsampling or downsampling layers, are used to reduce the spatial dimensions of the feature maps while retaining important information.
3) Activation Functions: Activation functions introduce non-linearity into the network, allowing it to learn complex relationships in the data.
4) Fully Connected Layers: After several convolutional and pooling layers, CNNs often end with one or more fully connected layers, similar to traditional neural networks.
Advantanges:
CNNs automatically learn complex features in a hierarchical manner, enabling effective representation of visual patterns from low-level to high-level details. Through convolution and pooling layers, CNNs preserve spatial hierarchies in images, crucial for tasks like object detection and localization. CNNs share weights across local regions, drastically reducing the number of parameters compared to fully connected networks, making them computationally efficient.
Disadvantanges:
CNNs, especially deep architectures, can require significant computational resources, making training and inference computationally expensive. CNNs often require large amounts of labeled data to generalize effectively, limiting their performance on tasks with limited datasets. Understanding why CNNs make specific decisions can be challenging due to their complex nature, leading to issues with interpretability and trust.
Architecture and Layers:
CNNs typically consist of multiple layers, including convolutional layers, pooling layers, activation functions, and fully connected layers.Convolutional layers use learnable filters to perform convolution operations that capture spatial features in the input data.Pooling layers reduce spatial dimensions and control overfitting by downsampling feature maps.
The input layer receives the raw pixel values of an image. The dimensions of the input depend on the size of the images being fed into the network. Convolutional layers are the core building blocks of a CNN. They consist of learnable filters that slide over the input data, performing convolution operations to extract features.Each filter learns to detect specific patterns, such as edges, corners, and textures.These layers create feature maps that represent learned features at different levels of abstraction. Activation functions like ReLU (Rectified Linear Activation) introduce non-linearity into the network, enabling it to learn complex relationships between features.The output layer produces the final predictions or classifications based on the features learned by the network.The number of neurons in this layer corresponds to the number of classes in a classification task.
Limitations:
1.Data Intensity and Overfitting: CNNs, especially deep architectures, require large amounts of labeled data for training. In cases of limited data, there’s a risk of overfitting, where the network memorizes the training data rather than generalizing to new data.
2.Translation Variance but Limited Rotation and Scale Invariance: While CNNs are translation invariant (can recognize patterns regardless of their position), they might struggle with recognizing objects at different scales or orientations without proper data augmentation.
3.Lack of Global Context: CNNs primarily focus on local receptive fields, which might lead to difficulties in capturing long-range dependencies and global context in an image.
4.High Computational Demands: Training and running deep CNNs can be computationally expensive, requiring powerful hardware (GPUs or TPUs) and longer training times. This limits their accessibility and usability in resource-constrained environments.
5.Interpretability and Explainability: CNNs’ complex internal representations make it challenging to understand why they make certain decisions.
6.Limited Robustness to Adversarial Attacks:CNNs are susceptible to adversarial attacks, where small, imperceptible modifications to input data can lead to incorrect predictions.
Future Work:
Future work aims to make CNNs more robust against adversarial attacks, ensuring that small perturbations in input data don’t lead to incorrect predictions. Researchers are working on techniques to provide better insights into CNN decisions, making them more transparent and interpretable for critical applications. Integrating information from various modalities, like images and text, can lead to more comprehensive understanding and better performance in tasks like image captioning and visual question answering.
Conclusion:
Convolutional Neural Networks have revolutionized computer vision and brought us closer to replicating human-level visual understanding. Their hierarchical feature learning, spatial hierarchies, and transfer learning capabilities have propelled them to the forefront of artificial intelligence. However, challenges like data intensity, interpretability, and robustness to adversarial attacks persist. As researchers and practitioners work to overcome these challenges, CNNs continue to drive advancements in fields ranging from healthcare to autonomous vehicles, shaping the future of AI-powered visual perception.