Information Retrieval in Natural Language Processing
September 8, 2023Information Retrieval (IR) revolves around a specialized software program with a key purpose: to efficiently manage, store, discover, and evaluate information held within collections of documents, primarily those containing text-based content. This intelligent system is tailored to assist users in locating the information they seek. However, it’s important to note that while the system aids in locating information, it might not always provide immediate answers to specific questions. Instead, it supplies valuable insights regarding the potential location of documents that might contain the desired information.
An effective IR system embarks on a mission to conjure documents that align with the user’s requirements. In simpler terms, its purpose revolves around presenting documents that truly resonate with what the user is actively searching for. This journey of finding and offering relevance is the heart of Information Retrieval, ultimately enabling users to make the most of the vast information landscape.
How a Typical Information Retrieval System Works
A typical Information Retrieval system seeks to bridge the gap between a user’s query and the relevant documents in a given collection. The procedure is divided into numerous steps:
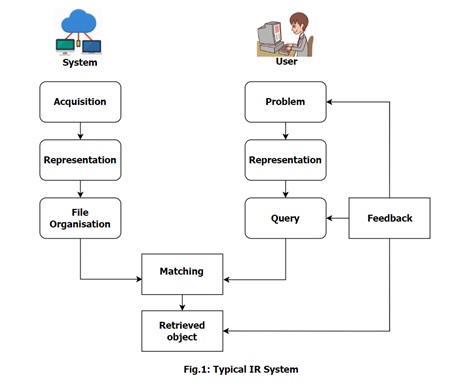
1. Acquisition: The acquisition step is crucial to the information retrieval process. This first phase is the careful selection of papers and other entities from a wide range of web resources with a wealth of text-based material. The use of web crawlers, which effectively collect the necessary data from many online corners, is the essential facilitator in this endeavor. The gathered data is then methodically placed in a database, serving as the basis for the succeeding steps.
2.Representation: The representation step is crucial, as it includes the subtle skill of indexing. This technique combines human-guided and automated procedures, as well as the use of regulated language and unrestricted textual phrases. An example of this step may be found in the realms of summary and bibliographic delineation. Elements such as the author’s identity, the importance of the title, the provenance of the source, the time dimension, and metadata complexities come together here, resulting in a thorough abstraction of the material.
3. File Organization: Two independent strategies come into play in the world of file arrangement, each offering a particular component to the seamless information retrieval tapestry. The first method, sequential organization, organizes documents based on their inherent data properties. The inverted organization strategy, on the other hand, comprises the creation of a record roster that is classified based on words. As these strategies interact, a novel synergy arises, combining their strengths to build a holistic file organizing solution.
4. Query: The formulation of a question is frequently used to signal the start of the information retrieval process. When a user expresses their information demands, the IR process begins. This point serves as a spark, igniting the inquiry. Search phrases are rigorously stated as formal statements of the user’s informational requirements in cases similar to web search engines. It is worth noting that an IR query does not need the specific identification of each item in the collection. Instead, the query serves as a beacon, aligning with a wide range of possibly related objects, although to varied degrees.
Key Issues in Information Retrieval (IR)
Three crucial issues are at the forefront of the field of information retrieval (IR): document and query indexing, query evaluation, and system evaluation. Let’s examine each of these issues in further detail to learn more about their importance.
1. Document and Query Indexing:
At the heart of information retrieval lie the tasks of Document and Query Indexing. The primary objectives here encompass deciphering meaningful interpretations from textual content and constructing internal representations. To achieve this, factors like completeness, computational manageability, and semantic accuracy must be carefully considered. The aim is to ensure that the indexing process facilitates efficient and accurate information retrieval.
2. Query Evaluation:
Query Evaluation, another cornerstone of IR, deals with translating documents into representations that align with selected keywords within the retrieval model. Furthermore, it entails assessing the similarity between document and query representations to derive relevant scores. In the context of information systems, IR confronts uncertainties and ambiguities:
Uncertainty: The existing representation of objects, such as images or videos, often falls short of capturing their underlying semantic nuances.
Vagueness: Users may not explicitly articulate their information needs or might express them in general terms, posing challenges in comprehending their inquiries, feedback, or actions.
3. System Evaluation:
The realm of System Evaluation delves into the imperative task of gauging the impact of the dispensed information on user success. Here, the interplay between time and space becomes a focal point, influencing the efficacy of a given system. Assessing the efficiency and effectiveness of the system is crucial to optimize its performance and user experience.
Types of Information Retrieval (IR) Models
Information Retrieval (IR) models form the bedrock of the efficient extraction of relevant information from vast datasets. These models can be broadly categorized into three main groups: Classical IR Models, Non-Classical IR Models, and Alternative IR Models. Let’s delve into the distinct characteristics and applications of each type.
1. Classical IR Models
a) Boolean Model: This straightforward model operates on the principles of Boolean logic. It transforms data into Boolean expressions and queries, seeking matches that satisfy the expression’s conditions. The model uses operations like AND, OR, and NOT to generate combinations of terms that match user queries.
b) Vector Space Model: Here, documents and queries are represented as vectors in a multi-dimensional space. The relevance of documents is determined by the similarity between their vectors and the query vector. The Binary Vector Space Model and the Weighted Vector Space Model are two variations of this approach.
c) Probability Distribution Model: This model gauges the similarity between query and document phrase representations. This can be accomplished by assessing entropy or estimating a document’s potential usefulness. The Expected-utility-based Probability Distribution Model and the Similarity-based Probability Distribution Model are two main versions of this model.
d) Probabilistic Models: Probabilistic models rank documents based on the probability of relevance to a query. Documents are ordered by their likelihood of being pertinent to the search query.
2. Non-Classical IR Models
Non-Classical IR Models challenge the conventional notions of IR. They operate on concepts beyond probability, similarity, and Boolean operations. Examples of non-classical models include information logic models, situation theory models, and interaction models.
3. Alternative IR Models
Alternative IR Models bridge traditional IR concepts with methodologies from other disciplines. These models offer innovative ways to enhance retrieval efficiency. Examples of alternative models encompass cluster models, fuzzy models, and latent semantic indexing (LSI) models.
Significance and Future Directions in Information Retrieval
Information Retrieval (IR) plays a pivotal role in modern information consumption, enabling us to swiftly access relevant knowledge from the vast digital landscape. As technology advances, the field is poised for exciting developments. Natural Language Processing (NLP) integration promises more accurate query understanding, while machine learning will refine retrieval precision. Moreover, contextual understanding through semantic analysis will enhance result relevance. Personalized search and multimodal retrieval will cater to individual preferences and diverse content types. Ethical considerations around data privacy and bias mitigation will also shape the future of IR. In essence, IR is bound to remain a dynamic force, continuously enriching how we engage with information.
In conclusion, information retrieval in NLP is an evolving field that empowers users to extract valuable insights from massive textual data. While facing challenges like ambiguity and user intent, various models have been developed to enhance the accuracy of retrieval systems. As technology progresses, these models will undoubtedly become more sophisticated, driving the efficiency of modern information retrieval applications.