Random Forests: A Versatile Ensemble Learning Approach
May 4, 2024In the field of machine learning, Random Forests have garnered significant attention and acclaim for their robustness, versatility, and effectiveness in solving classification and regression problems. This ensemble learning technique, which combines the predictions of multiple decision trees, has found widespread applications across various domains, including finance, healthcare, marketing, and more. In this comprehensive guide, we will delve into the intricacies of Random Forests, exploring their underlying principles, construction methodology, advantages, and real-world applications. Through detailed explanations and practical examples, readers will gain a profound understanding of Random Forests and their significance in modern data science.
Understanding Random Forests
Random Forests are a popular ensemble learning algorithm used for classification and regression tasks. They belong to the family of tree-based methods, where the underlying model is a collection of decision trees. The “forest” in Random Forests refers to this collection of trees, and the “random” component stems from the randomness injected into the model during training.
Key Components of Random Forests
Random Forests consist of number of key components, each playing an important role in the algorithm’s construction and operation.
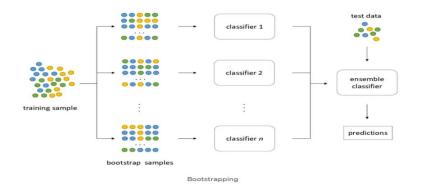
Decision Trees: The decision trees are the building blocks of Random Forests. Each decision tree is trained on a subset of the training data by using a random selection of features.
Bootstrap Sampling: Random Forests employ a technique called bootstrap sampling to create multiple subsets of the original training data. This technique involves randomly sampling with replacement from the training dataset to generate diverse datasets for training individual trees.
Random Feature Selection: At each node of a decision tree, a random subset of features is considered for splitting. This randomness ensures that each tree learns from a different subset of features, leading to diverse and uncorrelated trees in the ensemble.
Construction of Random Forests
The step-by-step explanation of the procedure for the Random Forest machine learning algorithm can be given by the following steps.
Step 1: Data Preparation
Input Data: Involves collecting the dataset containing features and corresponding target labels.
Data Cleaning: Handle missing values, outliers, and other data inconsistencies present. Feature Engineering: If necessary, perform feature selection, transformation, or extraction to enhance the predictive power of the features.
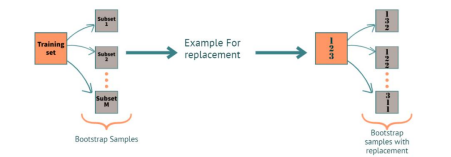
Step 2: Bootstrap Sampling
Random Sampling: Create multiple random samples (with replacement) from the original dataset. Each sample will have the same size as the original dataset but may contain duplicate instances.
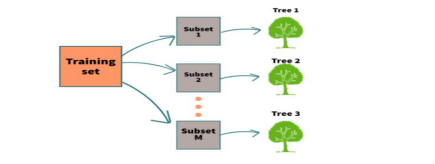
Step 3: Tree Construction
Decision Tree Building: For each bootstrap sample, build a decision tree using a subset of features.
Random Feature Selection: At each node of the decision tree, consider only a random subset of features for splitting.
Recursive Splitting: Recursively split the data at each node based on the selected features until reaching a stopping criterion, such as reaching a maximum depth or minimum number of samples per leaf.
Step 4: Aggregation of Predictions
Prediction: Once all decision trees are constructed, make predictions for new instances by aggregating the predictions of individual trees.
Classification: For classification tasks, use a majority voting scheme to determine the final class label.
Regression: For regression tasks, calculate the average of the predictions from all trees as the final output.
Advantages of Random Forests
Random Forests offer several advantages over traditional machine learning algorithms, making them a popular choice for a wide range of applications.
Robustness: One of the key advantages of Random Forests is their robustness to overfitting. By aggregating the predictions of multiple trees, Random Forests reduce the variance of the model and improve its generalization performance.
Versatility: Random Forests can handle a variety of data types, including categorical and numerical features, as well as missing values. They are also robust to outliers and noise in the data, making them suitable for real-world datasets with diverse characteristics.
Feature Importance: Random Forests provide a measure of feature importance, which indicates the contribution of each feature to the model’s predictive performance. This information can be used for feature selection, dimensionality reduction, and gaining insights into the underlying data patterns.
Applications of Random Forests
Random Forests find applications across a wide range of domains, including but not limited to:
Finance: In finance, Random Forests are used for credit scoring, where they analyse customer data to assess creditworthiness and predict the likelihood of default. They are also employed in fraud detection, helping financial institutions identify and prevent fraudulent activities by analysing transactional data and customer behaviour patterns.
Healthcare: In healthcare, Random Forests play a crucial role in disease diagnosis, leveraging patient data such as symptoms, medical history, and diagnostic test results to predict the likelihood of diseases. They are also utilized in drug discovery, assisting pharmaceutical researchers in identifying potential drug candidates by analysing chemical compounds and predicting their biological activities.
Marketing: Random Forests aid marketers in customer segmentation, where they analyse demographic, behavioural, and transactional data to identify distinct customer segments. Additionally, they are used in churn prediction, helping businesses predict and mitigate customer churn by analysing customer engagement metrics and usage patterns.
Conclusion
Random Forests offer a versatile and powerful approach to solving classification and regression problems. By leveraging the collective wisdom of multiple decision trees, Random Forests achieve robustness, versatility, and high predictive accuracy. Their ability to handle diverse datasets and provide insights into feature importance makes them a valuable tool in the arsenal of machine learning practitioners. As the field of machine learning continues to evolve, Random Forests are likely to remain a popular choice for a wide range of applications.
In this guide, we have explored the Random Forest algorithm in detail, covering its construction, advantages, and applications. Through practical examples and explanations, readers should now have a thorough understanding of Random Forests and how they can be used to tackle real-world problems in machine learning.