
Exploring NoSQL Data Architectures for Big Data Applications
February 5, 2025NoSQL databases have become a potent substitute for conventional relational databases as businesses handle ever-increasing volumes of data. These systems are made to meet the demands of Big Data, which include managing a variety of data kinds at high velocity and in enormous numbers. The four primary NoSQL data architectures—graph databases, document databases, column family stores, and key-value stores—will be discussed in this article. We will also contrast the ways in which different systems tackle Big Data issues, particularly those in which relational databases are inadequate.
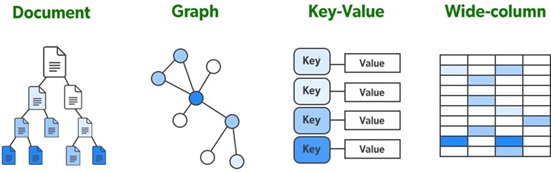
Types of NoSQL Data Architectures:
1. Key-Value Stores
The most basic type of NoSQL database is a key-value store, which is made to hold data in pairs of distinct keys and the values that go with them. This design is frequently used in caching systems and session management since it is optimized for quick lookups.
- Functionality: Key-value storage, like dictionaries, enable data retrieval through the use of keys. They may not handle sophisticated querying patterns, yet they are very effective for simple queries.
Examples:
- Redis:
- In-Memory Data Structure Store: Redis is a very fast read/write system since it runs mostly in memory.
- Distributed Caching: Redis is a popular tool for data caching in distributed applications because it can manage high traffic levels without causing performance bottlenecks.
- Memcached:
- Memcached is a distributed memory object caching system that speeds up web applications by minimizing database load.
- Web application acceleration: It quickens response times by keeping frequently requested data in memory and speeding up apps.
2. Graph Databases
Graph databases are best suited for handling and storing data from naturally related sources, like supply chain networks, social networks, and recommendation systems. They use edges— relationships—and nodes—entities—to store data.
- Functionality: Graph databases are particularly well-suited for applications like pathfinding or data clustering that call for intricate querying of linked data and relationships.
Examples:
- Neo4j:
- Native Graph Data Model: Neo4j’s architecture is designed to handle large amounts of densely connected data, making storage and retrieval effective.
- Highly Connected Data Modeling: It is perfect for recommendation engines, social networks, and fraud detection since it is excellent at querying complex relationships.
- Apache TinkerPop:
- Graph Computing Framework: TinkerPop is an application development framework that makes it easier for programmers to query graph databases while creating graph-based apps.
- Polyglot Persistence: It provides versatility when working with many storage backends by supporting a variety of graph databases via a single interface.
3. Column family
Column family stores organize data into rows and columns, similar to relational databases but with more flexibility. Each row in a column family store can have a variable number of columns, making it efficient for handling sparse data and time-series data.
- Functionality: These databases provide flexibility in both reads and writes, making them perfect for use cases where wide-column datasets are kept across several servers.
Examples:
- Apache Cassandra:
- Horizontal scalability is supported by Cassandra, a distributed wide-column store that is well-known for its capacity to handle massive datasets across dispersed servers.
- High Availability and Fault Tolerance: Because it eliminates the possibility of a single point of failure, it is a well-liked option for applications that need to be available always.
- HBase:
- Hadoop-Based Column Family Database: HBase is made to handle real-time Big Data and is based on Hadoop’s HDFS.
- Real-time analytics is a popular technology for applications that need to receive and write large amounts of data quickly.
4. Document Databases
Structured documents, typically in JSON or BSON format, are used by document databases to store data. Because of this architecture’s great flexibility, applications handling unstructured or semi-structured data can benefit from schema-less design.
- Functionality: Unlike relational databases, documents do not require a preset schema in order to store nested data structures. These are very helpful for data lakes and content management systems.
Examples:
- MongoDB:
- Flexible Schema Design: Dynamic schemas are supported by MongoDB, enabling a variety of structures for each document.
- Rich Query Features: It is appropriate for a range of applications since it provides strong querying choices such full-text search, aggregation, and indexing.
- Apache CouchDB:
- RESTful HTTP API: CouchDB is a well-liked option for web applications since it employs a RESTful API for database connectivity.
- Offline-First Applications: CouchDB offers data synchronization across devices, making it a good fit for mobile and offline-first applications.
Solving Big Data Issues with NoSQL
Relational databases frequently suffer with scalability, high availability, and flexibility. NoSQL databases, on the other hand, are designed to overcome the issues that arise while processing Big Data.
- Massive Scalability
- NoSQL databases are excellent at horizontal scaling, distributing data among several servers to handle increasing data volumes.
- Distributed Processing: By effectively allocating tasks across nodes, they guarantee scalability without compromising performance.
- High Availability
- Fault Tolerance: NoSQL systems are designed to be resilient, which means that even in the event of a node failure, the system will continue to function.
- Automatic Replication: In the event of a hardware failure, data is preserved through replication among several nodes.
- Flexible Data Models
- Schema-Less design: NoSQL databases enable the storage of unstructured or semi- structured data using a schema-less design.
- Heterogeneous Data Integration: By integrating different kinds of data, these systems can support Big Data applications that depend on a variety of datasets.
Comparison of NoSQL Systems
- Performance
- Throughput: Real-time data streams and other high-throughput applications are well-suited for NoSQL databases.
- Latency: NoSQL systems provide low-latency replies, even under high load, thanks to in-memory solutions like Redis.
- Data Models
- Structure: A wide range of applications, from basic caching to intricate data modeling, are made possible by the flexibility of NoSQL databases (key-value, graph, column family, and document).
- Querying: The various NoSQL types offer a variety of querying capabilities, such as graph traversal in Neo4j or MapReduce in HBase.
- Consistency and Availability
- CAP Theorem Tradeoffs: In distributed situations, NoSQL databases frequently forgo rigorous consistency in favor of eventual consistency, giving availability and partition tolerance top priority.
- Eventual Consistency: High availability is ensured by data that, while it may not be instantly consistent across all nodes, will eventually converge.
Conclusion
Many of the difficulties that traditional relational databases face in handling Big Data applications are resolved by NoSQL databases. NoSQL systems provide customized solutions, ranging from the ease of use of key-value stores, to the connected data modeling of graph databases, the scalability of column family stores, and the flexibility of document databases. Businesses may choose which NoSQL system best suits their Big Data demands by knowing the advantages and disadvantages of each architecture.