Vanilla RNNs and Their Limitations
February 5, 2025Recurrent Neural Networks (RNNs) are a class of neural networks designed for processing sequences of data, such as time series, text, and speech. They are particularly useful when the data has a temporal or sequential structure because RNNs have a “memory” component that enables them to capture dependencies between different steps in a sequence. One of the simplest forms of RNN is known as the Vanilla RNN.
Understanding Vanilla RNNs
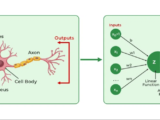
A Vanilla RNN consists of a network of neurons that operate in a recurrent fashion, meaning they maintain a hidden state that gets updated as they process each element in the input sequence. This hidden state is shared across time steps, enabling the RNN to “remember”
information from previous steps, which is crucial for tasks like speech recognition, machine translation, and time-series forecasting.
Architecture of a Vanilla RNN
In its simplest form, a Vanilla RNN operates in the following way:
Input: At each time step ttt, the RNN takes an input xtx_txt from the sequence.
Hidden State Update: It maintains a hidden state hth_tht, which is updated based on the current input and the hidden state from the previous time step. This can be expressed mathematically as:

Where:
- Wh and Wx are weight matrices.
- Ht-1 is the hidden state from the previous time step.
- b is the bias term.
- tanh is the activation function, though other activation functions can also be used.
- Output: After processing the sequence, the RNN generates an output, which can either be at each time step or only at the final step, depending on the task. The output is computed based on the hidden state, and for classification tasks, a softmax function is often used to get a probability distribution over possible outputs.
The key aspect of Vanilla RNNs is that the hidden state acts as the “memory” of the network, enabling it to process sequences of arbitrary length.
Applications of Vanilla RNNs
Due to their ability to handle sequential data, Vanilla RNNs have been applied in several areas:
- Natural Language Processing (NLP): Tasks like language modeling, where predicting the next word in a sequence depends on understanding previous words, make use of RNNs.
- Time Series Prediction: RNNs can be applied to forecast future values based on historical data, such as in stock market prediction or weather forecasting.
- Speech Recognition: RNNs can capture the dependencies between phonemes and words, making them suitable for recognizing spoken language.
However, despite their potential, Vanilla RNNs have certain limitations that hinder their performance on more complex tasks.
Limitations of Vanilla RNNs
While Vanilla RNNs perform well on short sequences, they struggle when tasked with
learning long-term dependencies, which significantly limits their applicability. The main limitations of Vanilla RNNs include:
Vanishing Gradient Problem
One of the most significant limitations of Vanilla RNNs is the vanishing gradient problem, which occurs when the gradients of the loss function, used to update the model’s weights during training, become extremely small. As the gradients backpropagate through time, they tend to shrink exponentially, especially when dealing with long sequences. This leads to:
- The weights failing to update properly.
- The network being unable to capture long-range dependencies.
- Gradients effectively “disappearing” over time steps.
The vanishing gradient problem makes Vanilla RNNs incapable of learning dependencies that are distant in the sequence. This is problematic for tasks that require remembering
information over long time spans, such as understanding long paragraphs of text or analyzing long historical time series.
Exploding Gradient Problem
Opposite to the vanishing gradient problem is the exploding gradient problem, where the gradients grow exponentially during backpropagation. This results in extremely large weight updates, which can cause the model to diverge rather than converge. Although exploding gradients can be mitigated through techniques like gradient clipping, they still pose a
challenge for Vanilla RNNs, particularly in tasks requiring very deep networks or long sequences.
Difficulty in Capturing Long-Term Dependencies
Due to the vanishing gradient problem, Vanilla RNNs are particularly poor at capturing long- term dependencies. When the important information in the sequence is many time steps away from the current point, the hidden state becomes less effective at retaining this information.
This is a critical issue in many real-world tasks, such as understanding the meaning of a sentence in NLP or tracking trends in time-series data over long periods.
Memory Constraints
Vanilla RNNs have limited memory capacity due to their simple recurrent structure. The hidden state must condense all relevant information from the previous steps into a fixed-size vector. As sequences grow longer, the RNN’s memory becomes too constrained to retain the necessary information, leading to a loss in performance.
Sequential Computation
Vanilla RNNs process sequences in a step-by-step manner, meaning that the computation of the hidden state at each time step depends on the previous time steps. This limits the
parallelization of the model, as future steps cannot be computed until the current step is completed. This sequential nature results in slower training times compared to feedforward neural networks or models like Transformers, which can process entire sequences in parallel.
Alternatives to Vanilla RNNs
To overcome these limitations, more advanced RNN architectures have been developed, including:
Long Short-Term Memory (LSTM)
LSTMs are designed to address the vanishing gradient problem by introducing gates that regulate the flow of information. The gates control what information is retained, forgotten, or passed on, allowing LSTMs to capture long-term dependencies more effectively than Vanilla RNNs.
Gated Recurrent Units (GRU)
GRUs are a simplified version of LSTMs, with fewer gates, making them computationally more efficient while still addressing the vanishing gradient issue. GRUs have been shown to perform comparably to LSTMs in many sequence-related tasks.
Transformer Networks
The introduction of Transformer architectures, which rely on self-attention mechanisms instead of recurrent structures, has revolutionized sequence modeling, especially in NLP. Transformers are capable of capturing both short- and long-range dependencies more effectively and allow for parallel computation, dramatically improving training speed and performance.
Conclusion
Vanilla RNNs, while foundational to the development of sequence modeling, have significant limitations when it comes to handling long-term dependencies, training stability, and
parallelization. The vanishing and exploding gradient problems severely restrict their ability to perform well on tasks that require memory over long sequences. However, architectures
like LSTMs, GRUs, and Transformers have emerged to address these shortcomings, enabling more effective and scalable solutions for sequential data processing. Despite their limitations, Vanilla RNNs remain an important building block in the history of deep learning, offering key insights into how neural networks can be adapted for sequence- based tasks.