

Introductory Guide to Decision Trees: Solving Classification Problems
May 4, 2024Decision trees are a powerful and widely used machine learning technique for solving classification problems. They provide a visual representation of possible decisions and their potential consequences, making them easily interpretable for both experts and non-experts in the field. In this article, we will explore the fundamental principles of decision trees, how they work, real-world applications across domains such as healthcare, finance, and marketing, as well as different types of decision tree algorithms.
The Basics: How Decision Trees Work
A decision tree is a flowchart-like structure where each internal node represents a feature or attribute; branches represent decisions or rules based on those features; and leaf nodes represent outcomes or predictions. The process begins with selecting the most important feature that best separates the data into different classes.
The selection process involves evaluating several measures such as information gain (ID3 algorithm), gain ratio (C4.5 algorithm), or Gini impurity (CART algorithm). These measures quantify how much information is gained by splitting the data based on certain attributes.
Once a feature is selected for splitting at an internal node, it divides the dataset into distinct partitions based on its values. This process continues recursively until reaching leaf nodes that predict class labels.
Feature Selection and Splitting
The primary goal during feature selection is to find attributes that offer maximum discrimination between different classes in order to create more homogeneous subsets within each branch of the tree. As mentioned earlier, various metrics can be utilized depending on which algorithm you choose – information gain evaluates how much entropy decreases after splitting using an attribute’s values; gain ratio accounts for potential bias towards attributes with many outcomes when calculating information gains due to their higher number compared to other possible attributes; Gini impurity calculates the probability that a randomly selected element from the dataset will be misclassified if it were randomly labeled according to the distribution of class labels in each partition.
Splitting is an iterative process that partitions data based on certain attribute values. Each split refines predictions by creating more homogeneous subsets within classes. For example, if you’re predicting whether or not someone will buy a product based on age and income, splitting might segment customers into different age groups or income brackets, allowing for more precise predictions.
Handling Overfitting
While decision trees are known for their interpretability and simplicity, they can easily become too complex and overfit the training data. Overfitting occurs when a tree captures noise or random fluctuations rather than true underlying patterns in the data. To address this issue, several techniques can be employed
Pruning: Pruning
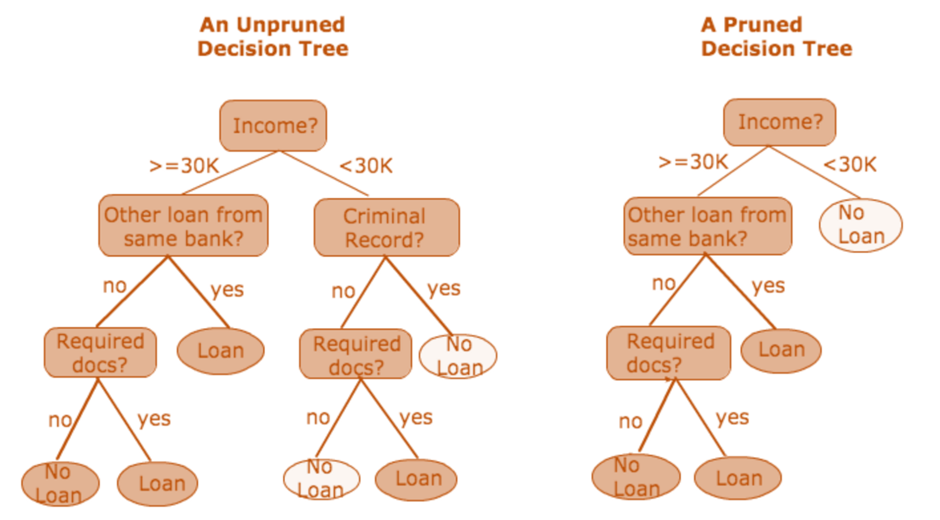
is a method used in decision tree algorithms to streamline the structure of the tree by eliminating unnecessary branches. This process helps in reducing complexity and curbing overfitting, which occurs when the model captures noise or random fluctuations in the training data rather than learning the underlying patterns. There are various strategies for pruning, among which are cost-complexity pruning and reduced error pruning.
Cost-complexity pruning, often employed in algorithms like CART (Classification and Regression Trees), involves assigning a cost to each node in the tree and iteratively removing the nodes that contribute the least to reducing overall complexity while maintaining or improving performance. On the other hand, reduced error pruning, commonly used in algorithms like C4.5, evaluates the impact of removing a node based on the reduction in classification errors it causes.
Cross-Validation: Cross-validation is a technique used to evaluate the performance of a predictive model. In k-fold cross-validation, the dataset is divided into k subsets or folds. The model is trained on k-1 folds and tested on the remaining fold, and this process is repeated k times, each time using a different fold as the test set. The results are averaged to obtain a more robust estimate of the model’s performance, helping to assess how well the model generalizes to unseen data. Cross-validation is crucial for detecting overfitting and selecting models with optimal hyperparameters.
Early Stopping: Early stopping is a regularization technique used in training algorithms, including decision trees, to prevent overfitting. Instead of training the model until it perfectly fits the training data, early stopping interrupts the training process when the performance on a validation dataset ceases to improve significantly. This is typically monitored by tracking a metric such as accuracy or loss on the validation set. By halting the training early, early stopping helps prevent the model from memorizing noise in the training data and encourages it to learn more generalizable patterns, ultimately improving its performance on unseen data.
The Power of Decision Trees: Real-World Applications
The versatility of decision trees has led to their adoption in various domains where classification tasks are prevalent:
In Healthcare
In healthcare, decision trees have been used for disease diagnosis, treatment planning, prediction of disease progression, and identifying potential risk factors. Their ability to handle missing values makes them valuable for analyzing medical datasets.
In Finance
Decision trees find applications in finance for credit scoring, fraud detection, investment decision-making, and determining customer eligibility for financial products. They enable organizations to make data-driven decisions with minimal human bias.
In Marketing
Marketers utilize decision trees to profile customers based on demographics and preferences, personalize marketing campaigns, identify target audiences more effectively, optimize pricing strategies, and predict customer churn.
Different Types of Decision Tree Algorithms
There are several algorithms used in implementing decision trees:
- ID3 (Iterative Dichotomiser 3): Developed by Ross Quinlan in 1986 as a predecessor to the C4.5 algorithm. ID3 uses information gain as its splitting criterion but has limitations when dealing with continuous attributes or missing data.
- C4.5: An extension of ID3 that overcomes some of its limitations. It introduced gain ratio as an alternative splitting criterion that addresses the bias towards attributes with many outcomes found in information gain calculations.
- CART (Classification And Regression Trees): Unlike ID3 and C4.5 which generate only classification trees, CART can build both classification and regression trees depending on the type of output variable it is trying to predict.
In Conclusion
In summary, decision tree algorithms offer a robust framework for classification tasks across various sectors while maintaining interpretability. Techniques such as pruning and cross-validation mitigate overfitting, enhancing generalization to unseen data. Real-world applications highlight their effectiveness in critical domains like healthcare and finance. Different algorithmic variants cater to diverse requirements, ensuring versatility in problem-solving. Decision trees’ transparent nature and high accuracy render them a preferred choice in machine learning. As technology advances, decision tree algorithms are poised to evolve further to meet the demands of increasingly complex datasets.
