
Unlocking the Power of Data Augmentation with Generative Adversarial Networks (GANs)
February 6, 2025In today’s data-driven world, having a rich dataset is crucial for building effective machine learning models. However, collecting high-quality data can be a challenge, especially in specialized fields like healthcare or autonomous driving. Enter Generative Adversarial Networks (GANs)—a groundbreaking approach that revolutionizes data augmentation by generating high-quality synthetic data.
What Are GANs?
Generative Adversarial Networks, introduced by Ian Goodfellow in 2014, consist of two main components: a generator and a discriminator. They engage in a unique game:
Generator (G): This network creates synthetic data from random noise. Its goal is to produce data that closely resembles real data.
Discriminator (D): This network evaluates data and distinguishes between real and synthetic instances. Its goal is to correctly identify whether the input data is real or generated.
The two networks are trained together in an adversarial manner, meaning that as the generator improves its data generation, the discriminator also becomes better at distinguishing real from fake data. This iterative process enhances the generator’s ability to create increasingly realistic outputs.
Architecture of GANs
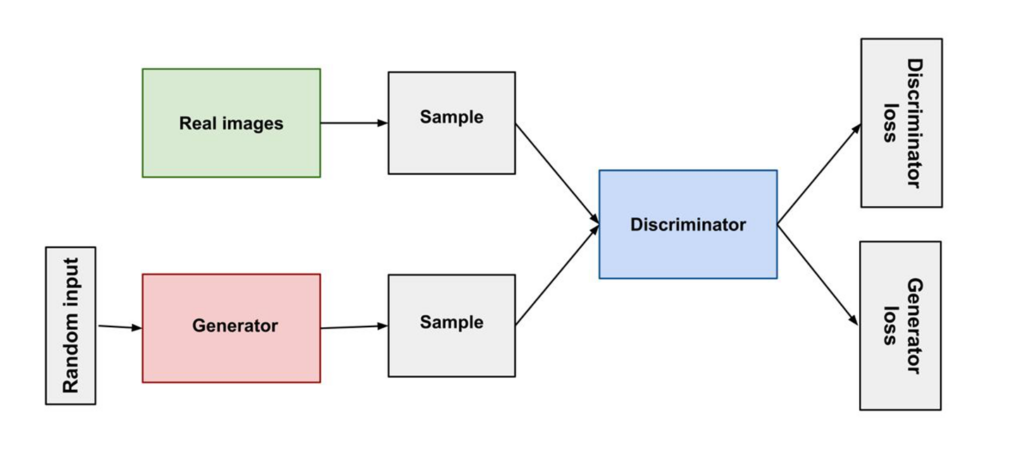
Generator (G):
Purpose: The generator’s goal is to produce synthetic data that resembles real data.
Input: It takes random noise as input, usually sampled from a Gaussian or uniform distribution. This randomness allows the generator to produce diverse outputs.
Process: The generator transforms the noise through a series of hidden layers, applying activation functions (such as ReLU or Leaky ReLU) to introduce non-linearity. The output can be any type of data (e.g., images, text).
Output Layer: The generator typically uses a tanh or sigmoid activation function to normalize the output to a specific range.
Discriminator (D):
Purpose: The discriminator’s role is to distinguish between real and synthetic data.
Input: It receives both real data (from the training dataset) and synthetic data (produced by the generator).
Process: Similar to the generator, the discriminator processes the input through hidden layers using activation functions. It learns to identify features that differentiate real from fake data.
Output Layer: The output is a probability score, typically using a sigmoid function, indicating the likelihood that the input is real (close to 1) or fake (close to 0).
Training a GAN is a dynamic and iterative process that requires careful tuning and monitoring. The goal is to reach a point where the generator produces high-quality synthetic data indistinguishable from real data, while the discriminator effectively evaluates the authenticity of both real and synthetic inputs. With the right strategies and practices in place, GANs can be a powerful tool for generating realistic data across a variety of applications. Key considerations for training GANs are—
Learning Rates: Choose learning rates carefully for both the generator and discriminator; often, the discriminator benefits from a higher learning rate for quicker adaptation to changes in generated data.
Batch Size: Adjust the batch size to influence convergence; larger batches can stabilize training, while smaller batches introduce noise that may help learn diverse representations.
Regularization Techniques: Implement techniques like dropout, batch normalization, or weight clipping to stabilize training and mitigate overfitting or mode collapse.
Monitoring for Mode Collapse: Regularly evaluate the diversity of generated samples to avoid mode collapse, and consider using techniques like mini-batch discrimination or feature matching to enhance output variety.
Training Dynamics: Train the generator and discriminator in a balanced manner to prevent instability; alternate training steps or adjust learning rates to ensure both networks improve together.
Top 4 libraries commonly used for training Generative Adversarial Networks (GANs):



Variations of GANs
Selecting the right type of GAN depends on your specific data characteristics, project requirements, and the level of control you want over the generated outputs. Understanding the strengths and ideal scenarios for each variation will help you make informed decisions and achieve optimal results in your generative modeling tasks.
| GAN Type | Ideal Use Cases |
| Conditional GANs (cGANs) | Use cGANs when you want to generate data based on specific conditions or attributes, such as generating images of a particular class (e.g., cats, dogs, or cars). |
| CycleGAN | Choose CycleGAN when you do not have paired training data. For instance, if you want to transform images from one domain to another (e.g., translating a horse image to a zebra image) without having corresponding pairs in the dataset. |
| StyleGAN | Use StyleGAN when you need to generate high-resolution images with adjustable styles and features. If you want to manipulate specific attributes like age, hairstyle, or expression in generated faces, StyleGAN is particularly effective. |
| Progressive Growing GANs | Use this variant when training GANs on high-resolution data, as it helps mitigate common issues like mode collapse and instability by gradually increasing complexity. |
GANs in Image Data Augmentation
One of the most notable applications of GANs is in the realm of image data augmentation. For instance, in medical imaging, GANs can generate synthetic images of rare diseases, providing valuable training data for convolutional neural networks (CNNs).
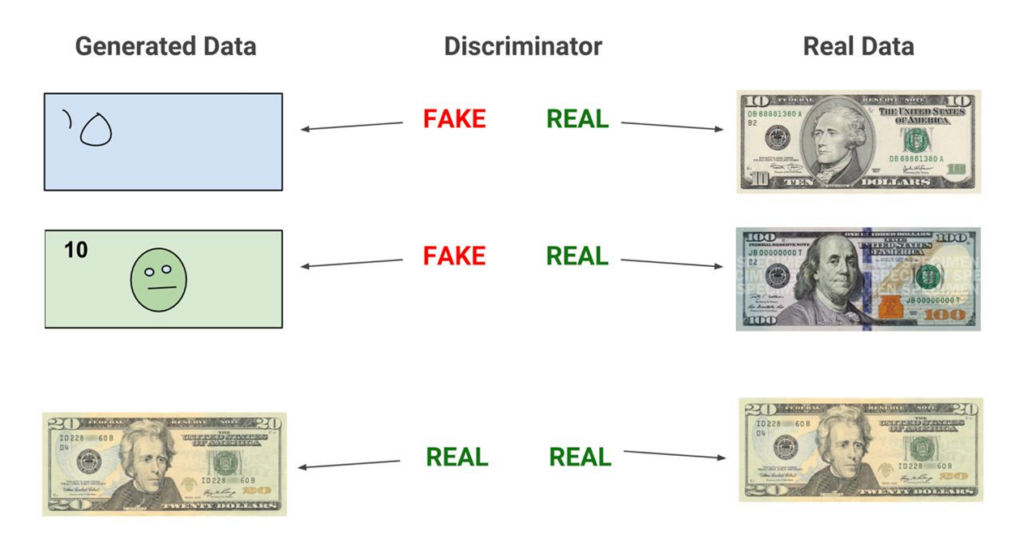
Fact Check – In a study focused on skin lesion classification, researchers used GANs to augment a limited dataset of melanoma images. The synthetic images generated by the GAN helped the CNN model improve its accuracy from 85% to over 90%. This demonstrates how GANs can enhance the diversity of the training data, allowing the model to learn better representations.
Advantages of Using GANs for Data Augmentation
GANs can produce a wide range of synthetic samples, increasing variability in the training dataset.
GANs can generate data for underrepresented classes, helping to balance datasets and improve model performance across all categories.
The quality of synthetic data generated by GANs is often high, making it difficult for models to distinguish between real and synthetic instances.
Challenges in Implementing GANs
The adversarial training process can be unstable, leading to issues like mode collapse, where the generator produces limited varieties of data.
Ensuring high-quality synthetic data requires rigorous evaluation and careful tuning of hyperparameters.
Training GANs can be computationally demanding, necessitating powerful hardware.
Conclusion
Generative Adversarial Networks have opened new avenues for data augmentation, enabling the generation of high-quality synthetic data that enhances machine learning model performance. As GAN technology evolves, its applications will likely expand across various domains, making it an essential tool for researchers and practitioners alike. Whether you are in healthcare, natural language processing, or video analytics, GANs can help you unlock the potential of your datasets and drive better outcomes.